TIL/Data Structures and Algorithms
(자료구조) 힙
parksisi
2021. 1. 26. 11:27
1. 힙 (Heap) 이란?
- 힙: 데이터에서 최대값과 최소값을 빠르게 찾기 위해 고안된 완전 이진 트리(Complete Binary Tree)
- 완전 이진 트리: 노드를 삽입할 때 최하단 왼쪽 노드부터 차례대로 삽입하는 트리. 무조건 왼쪽부터. (아래 힙 기본동작 그림 참조)
- 힙을 사용하는 이유
- 배열에 데이터를 넣고, 최대값과 최소값을 찾으려면 O(n) 이 걸림
- 이에 반해, 힙에 데이터를 넣고, 최대값과 최소값을 찾으면, 𝑂(𝑙𝑜𝑔𝑛) 이 걸림
- 우선순위 큐와 같이 최대값 또는 최소값을 빠르게 찾아야 하는 자료구조 및 알고리즘 구현 등에 활용됨
2. 힙 (Heap) 구조
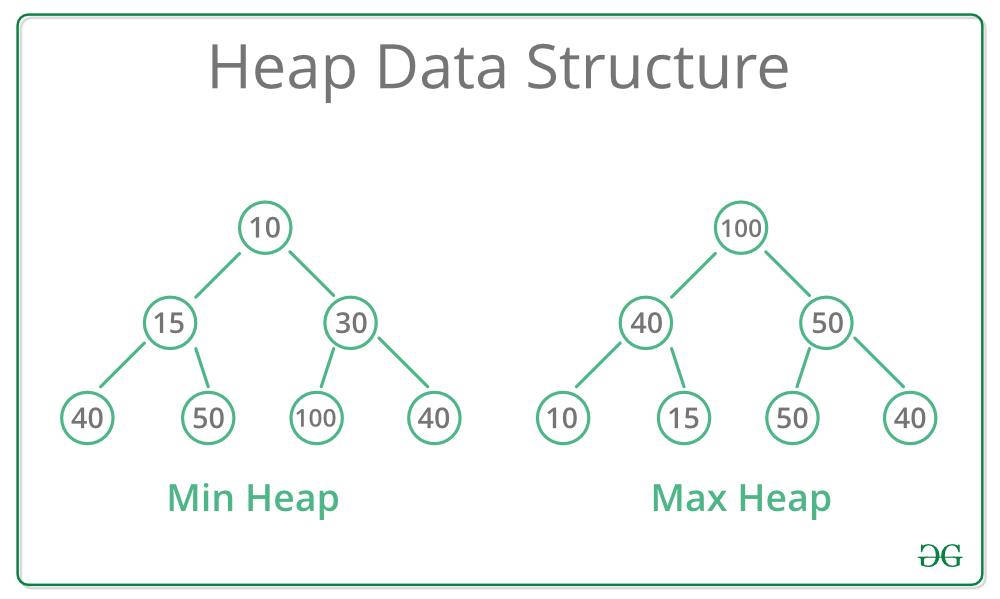
- 최대 힙과 최소 힙 존재
- 각 노드의 값은 해당 노드의 자식 노드 값보다 크거나 같다(최대 힙)
- 완전 이진 트리의 형태를 가짐
3. 힙과 이진 탐색 트리 비교
- 공통점 : 모두 이진 트리
- 차이점 : 힙은 각 노드의 값이 자식노드보다 크거나 같음(최대 힙), 이진 탐색 트리의 조건인 작은 값 왼쪽, 큰 값 오른쪽 규칙 없음
- 이진 탐색 트리는 탐색을 위한 구조라면 힙은 최대값/최소값을 구하기 위한 구조
4. 힙에 데이터 삽입하기
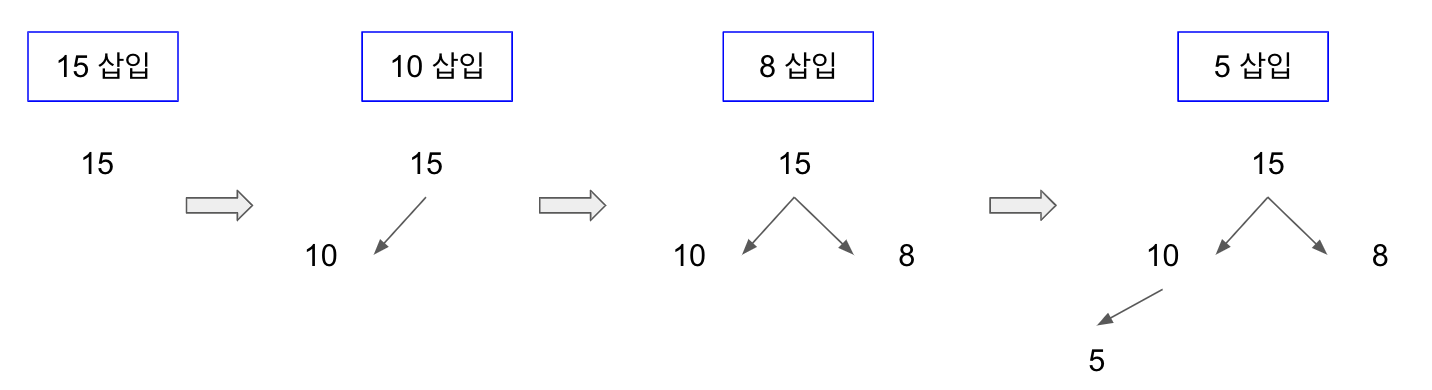
4.1 기본 동작
- 힙은 완전 이진 트리이므로, 삽입할 노드는 기본적으로 왼쪽 최하단부 노드부터 채워지는 형태로 삽입
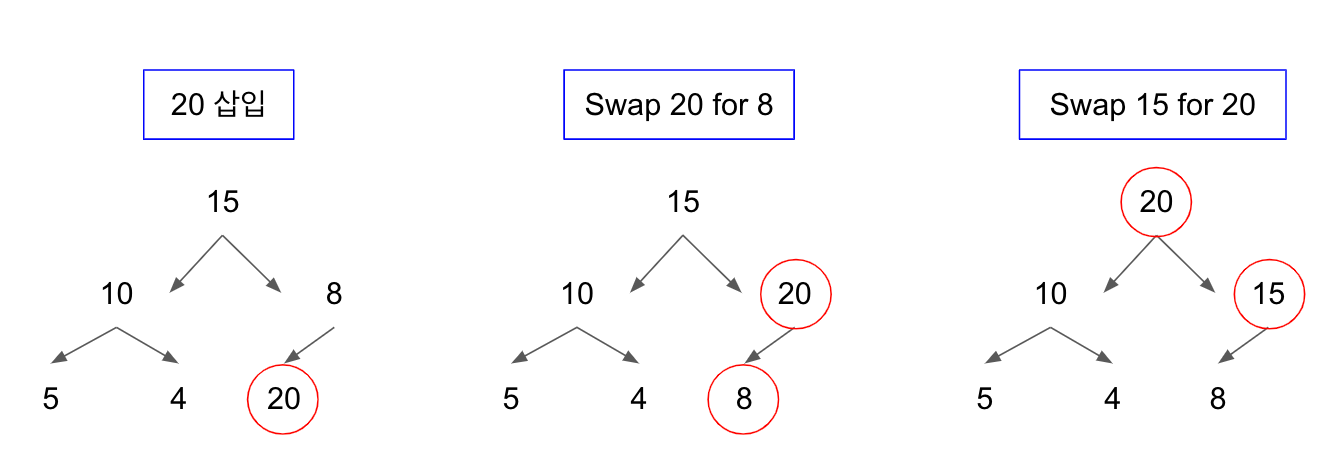
4.2 삽입할 데이터가 힙의 데이터보다 클 경우 (최대 힙)
- 일단 기본 동작에 맞춰 최하단부 왼쪽 트리부터 채워짐
- 채워진 노드 위치에서 부모노드의 값과 비교하여 클 경우 바꿔주는 작업 반복
4. 힙에 데이터 삭제하기
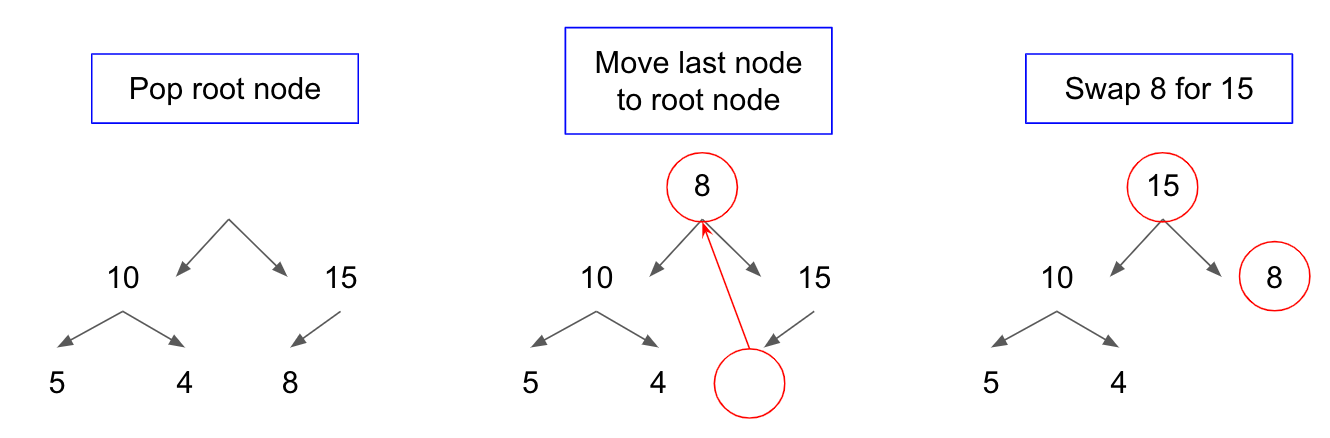
- 힙에서의 데이터 삭제는 일반적으로 루트노드의 값을 pop하는 것이다. 힙의 용도가 최대값, 최소값 탐색이기 때문에 항상 루트노드에 최대값 혹은 최소값이 위치한다
- 루트 노드의 값을 pop 한 후 가장 최하단부에 위치한 노드를 루트 노드로 이동
- 루트 노드 값이 자식 노드보다 작을 경우, 루트 노드의 자식 노드 중 가장 큰 값을 가진 노드와 위치를 바꿔주는 작업을 반복
5. 힙 구현
- 일반적으로 힙 구현시 배열 자료구조를 활용함
- 배열은 인덱스가 0번부터 시작하지만, 힙 구현의 편의를 위해, root 노드 인덱스 번호를 1로 지정하면, 구현이 좀더 수월함
- 부모 노드 인덱스 번호 (parent node's index) = 자식 노드 인덱스 번호 (child node's index) // 2
- 왼쪽 자식 노드 인덱스 번호 (left child node's index) = 부모 노드 인덱스 번호 (parent node's index) * 2
- 오른쪽 자식 노드 인덱스 번호 (right child node's index) = 부모 노드 인덱스 번호 (parent node's index) * 2 + 1
5.1. 데이터 삽입
- 일단은 데이터를 완전 이진 트리 구조에 맞춰 최하단부 왼쪽 노드부터 채운다
- 채워진 노드 위치에서, 부모 노드보다 값이 클 경우, 부모 노드와 위치를 바꿔주는 작업을 반복함 (swap)
class Heap:
def __init__(self, data):
self.heap_array = list()
self.heap_array.append(None) # # array의 1번인덱스부터 하는게 편하기때문에 0번 인덱스에는 none값을 임의로 넣는다
self.head_array.append(data)
def move_up(inserted_index):
if inserted_index <= 1:
return False
parent_index = inserted_index // 2
if heap_array(inserted_index) > heap_array(parent_index):
return True
else:
return False
def insert(self, data):
if len(self.heap_array) == 0:
self.heap_array.append(None)
self.heap_array.append(data)
return True
self.heap_array.append(data)
inserted_index = len(heap_array)-1
while self.move_up(inserted_index):
parent_index = inserted_index // 2
self.heap_array(inserted_index), self.heap_array(parent_index) = self.heap_array(parent_index), self.heap_array(inserted_index)
insert_index = parent_index
return True
5.2. 데이터 삭제
- 보통 삭제는 최상단 노드 (root 노드)를 삭제하는 것이 일반적임. 사실 삭제라기보단 pop이다.
- 힙의 용도는 최대값 또는 최소값을 root 노드에 놓아서, 최대값과 최소값을 바로 꺼내 쓸 수 있도록 하는 것이기때문
- 상단의 데이터 삭제시, 가장 최하단부 왼쪽에 위치한 노드 (일반적으로 가장 마지막에 추가한 노드) 를 root 노드로 이동
- root 노드의 값이 child node 보다 작을 경우, root 노드의 child node 중 가장 큰 값을 가진 노드와 root 노드 위치를 바꿔주는 작업을 반복함 (swap)
def move_down(popped_idx):
left_child_popped_idx = popped_idx * 2
right_child_popped_idx = popped_idx * 2 + 1
# case1 : 왼쪽 자식 노드 없을 때 (왼쪽이 없다는 말은 자식노드가 아예 존재하지 않는다는 의미)
if left_child_popped_idx >= len(self.heap_array):
return False
# case2 : 오른쪽 자식 노드만 없을 때
elif right_child_popped_idx >= len(self.heap_array):
if self.heap_array[popped_idx] < self.heap_array[left_child_popped_idx]:
return True
else:
return False
# case3 : 자식 노드 둘 다 있을 때
else:
# 먼저 자식 노드간 값 비교
if self.heap_array[left_child_popped_idx] > self.heap_array[right_child_popped_idx]:
if self.heap_array[popped_idx] < self.heap_array[left_child_popped_idx]:
return True
else:
return False
else:
if self.heap_array[popped_idx] < self.heap_array[right_child_popped_idx]:
return True
else:
return False
def pop(self):
if len(self.heap_array) <= 1:
return None
returned_data = self.heap_array[1]
self.heap_array[1] = self.heap_array[-1]
del self.heap_array[-1]
popped_idx = 1
while self.move_down(popped_idx):
left_child_popped_idx = popped_idx * 2
right_child_popped_idx = popped_idx * 2 + 1
# case2 : 오른쪽 자식 노드만 없을 때
if right_child_popped_idx >= len(self.heap_array):
if self.heap_array[popped_idx] < self.heap_array[left_child_popped_idx]:
self.heap_array[popped_idx], self.heap_array[left_child_popped_idx] = self.heap_array[left_child_popped_idx], self.heap_array[popped_idx]
popped_idx = left_child_popped_idx
# case3 : 자식 노드 둘 다 있을 때
else:
# 먼저 자식 노드간 값 비교
if self.heap_array[left_child_popped_idx] > self.heap_array[right_child_popped_idx]:
if self.heap_array[popped_idx] < self.heap_array[left_child_popped_idx]:
self.heap_array[popped_idx], self.heap_array[left_child_popped_idx] = self.heap_array[left_child_popped_idx], self.heap_array[popped_idx]
popped_idx = left_child_popped_idx
else:
if self.heap_array[popped_idx] < self.heap_array[right_child_popped_idx]:
self.heap_array[popped_idx], self.heap_array[right_child_popped_idx] = self.heap_array[right_child_popped_idx], self.heap_array[popped_idx]
popped_idx = right_child_popped_idx
return returned_data6. 시간 복잡도
트리의 높이를 h라고 한다면 데이터 삽입 혹은 삭제시 최악의 경우 루트노드에서 leaf노드까지 비교해야하므로 O(h)만큼의 시간복잡도가 걸린다. h는 logN에 가까우므로 시간복잡도는 O(logN)이다.
** 패스트캠퍼스의 '알고리즘/기술면접 완전 정복 올인원 패키지' 강의를 듣고 작성한 글입니다